
Previous Talks
- Home
- Previous Talks

In the rapidly evolving landscape of cybersecurity, botnets remain a significant threat to Kubernetes and containerization environments. In this talk, we will present a comprehensive overview of our latest research on new groups, delving into their organizational structures, codebases, and tactics. We will explore how these malicious actors share information, select their targets, and offer their services. By sharing our findings, we hope to raise awareness and facilitate a better understanding of these threats, ultimately contributing to the development of more effective countermeasures. Botnets represent a significant and evolving threat in the cybersecurity landscape. This presentation aims to shed light on the inner workings of these networks based on extensive research and real-world examples. Attendees will gain insights into: - Organization and Structure: Understanding how modern botnets are set up and managed. - Code Analysis: A deep dive into the types of code used by botnet operators to exploit container vulnerabilities. - Information Sharing: Exploring whether and how these networks share data amongst themselves. - Target Selection: Analyzing the methods and criteria used by botnets to choose and attack applications. Our aim is to provide a global view of the current state of botnets, offering valuable knowledge that can aid in the detection, analysis, and mitigation of these threats. This talk is designed for security professionals, researchers, and anyone interested in understanding the complexities and dangers posed by botnets in today’s digital world.

Are your applications really cloud native? As a developer, you must be concerned about who can access resources in your system. You probably think of authentication and authorization as any other logic – ifs and elses executed before performing critical operations Did you know the Kubernetes Role-Based Access Control and authentication can be wisely combined to other cloud native technologies to compose a platform that will help you avoid spaghetti code, implement best practices for application security as a true cloud native developer, while delegating some of the burden to other layers of your system? Attendees to this session will learn how to leverage Kube to build Zero Trust authorization the cloud native way. The talk will demo use cases of tailor-made data security leveraging cloud native technology, including Envoy and Open Policy Agent, that reclaim security policies as a proper concern, decoupled from the application's code at the same level as Deployments and Services.

A story of how our infrastructure evolved over time to accommodate an increasing number of users - from on-premise to cloud and back down. How does one make an infrastructure to handle more than a couple of users? How do you go from 100 to 1000 to 100,000 to tens of millions? What happens when due to popular demand hundreds of thousands of users hit your servers at the same time? I'll tell you a story of how a small team of people managed to move software and services from one server to two, and then to dozens on cloud and then back to on-premise. What we encountered on the way, where we failed, and how we solved it.

GenAI is not a brand new technology yet it has become a hot topic in the last couple of years. As many organisations are adopting it within different business cases, SREs and DevOps engineers have a great deal to say about its best use cases. This talk puts GenAI on the DevOps map, and deep dives into the GenAI applications within the DevOps/SRE realm. In this talk, I will revisit concepts and technologies linked to GenAI such as transformers, LLMs and RAG and see them applied into observability, in particular in the shape of the AI Assistant and focus on some use cases for DevOps engineers. Whether GenAI is really a must try technology, we will understand by the end of this talk.

When deploying an application to Kubernetes, each container in a pod should define CPU requests and limits. It is more commonly understood how CPU requests affect the scheduling of your pod and the future pods in the same node. But outside scheduling, CPU requests and limits have some effects on how your containers are created and can heavily impact their performance and their energy footprint. In this talk we will help clarify some misconceptions about CPU requests and limits by explaining, in a developer friendly way, how they translate to some Linux internals. We will offer some quick tips on how to understand those effects, minimise them, and select good values to reduce your application energy footprint while ensuring its performance.

Join us in this insightful session as we dive into the world of serverless architectures and explore common cost mistakes and learn actionable tips for cutting down wastes and reducing your AWS bill. Whether you're looking to cut down on CloudWatch costs or improve cost-efficiency for your serverless application, we've got some helpful tips, just for you.

This talk explores Fastly's journey in building and scaling its platform, highlighting key architectural principles and addressing the inherent challenges of achieving scalable growth. The focus is on understanding how Fastly prioritizes availability, horizontal scaling, data ownership, and a platform-centric approach. We’ll discuss the critical role of real-time monitoring and user feedback in our engineering cycles, ensuring that our platform evolves in response to actual usage patterns. Through concrete case studies, we’ll illustrate how these practices have led to measurable improvements in performance and user experience. Join us to learn how Fastly’s dedication to continuous improvement helps create a better internet where all experiences are fast, safe and engaging

Are you navigating the complexities of compliance frameworks like SOC2, CIS, and HIPAA and seeking a more efficient path? This talk breaks down these frameworks simply and shows you a time-saving trick, making it perfect for anyone wanting to make their organization's compliance journey much easier. I'll start by outlining the basics of these frameworks and highlighting the challenges businesses face in implementing them. As the creator and maintainer of the terraform-aws-modules projects, I'll be excited to share how using these open-source Terraform AWS modules can streamline the compliance process. I'll walk you through real-life examples showing how such solutions significantly reduce the effort and time required for compliance. At the end of the talk, attendees will get actionable insights on using Terraform AWS modules for efficient compliance management.

Many successful paradigms in engineering and computer science are the result of two distinct approaches colliding with each other, leading to broader and more powerful applications. In this talk, we’ll look at the parallel backgrounds of two established paradigms: SQL and Observability. We’ll be tracing back the history of both paradigms. How they managed to avoid each other despite SQL being the lingua franca of data manipulation, and how the industry standardization, fuelled by open-source innovation, has now propelled SQL back into the game as an observability language. We’ll also highlight case studies and benchmark results to provide the necessary elements for the attendee to answer a simple question: is Sql-based observability applicable to my use case? highlighting also the current limitations of this approach and leaving the conclusions for the attendees to draw. More info in: https://clickhouse.com/blog/the-state-of-sql-based-observability

In our upcoming presentation, we'll explore a cutting-edge architectural solution for real-time SMS and email notifications, particularly geared towards responding to earthquake events. This system is designed to handle rapid data transmission, listening for event changes every second, making it ideal for real time critical alert scenarios. Central to our discussion will be the integration of Lambda functions and Confluent Kafka, coupled with advanced multithreading techniques and DynamoDB lock strategies. A focal point of our presentation will be addressing the challenges and innovative solutions involved in integrating Confluent Kafka with Lambda functions to enable serverless operation of both producers and consumers. This is a key element in ensuring the quick and efficient distribution of notifications through parallel methods. Additionally, we will delve into the implementation of an automated scaling mechanism, which is vital for optimising the performance of the Serverless Notification ecosystem. Our aim is to provide a comprehensive insight into how these technologies can be effectively combined to develop a robust and efficient system, capable of delivering critical real-time alerts for situations like earthquake occurrences, ultimately playing a crucial role in saving human lives.

How to properly size a service through performance testing and take those metrics into production. The key lies in Observability. In the last 5 years, the Lidl Plus product has grown from 2 stores in Zaragoza to 13,000 stores across Europe. From 100,000 users in 2018 to 90million in 2024. To carry out this titanic work in an organized and budget-friendly manner, emphasis was placed on two relevant points: - Monitoring and Observability - Performance Testing Basic monitoring transitioned to a culture of Observability, which not only provided visibility into system metrics but also into the complete flow and user experience. When we talk about observability, we no longer talk about isolated systems but about understanding what happens as a whole. Performance testing was highly relevant throughout the rollout period, inferring the volume that each country would bring based on the number of tickets coming in from the stores. Performance tests were conducted for each critical product, and end-to-end tests were constantly performed to measure the user experience of the Lidl Plus app. We lacked real-time visibility from the application to the backend. Over the past 5 years, we have worked on that traceability to measure the "happiness" of our users, moving from tools like Firebase or Dynatrace to the current solution based on OpenTelemetry. We will show the current stack and the ability to infer performance data for a product before going into production, validating workload hypotheses and feedback to improve tests once they are in production.

Usage of GitOps methodology to deploy Infrastructure as code using Crossplane and ArgoCD: - Configuration of Crossplane to have rights to deploy infra from one tooling cluster to the rest of the target Accounts - Implementation new Infrastructure Kompositions in order to deploy Infrastructure as CRD’s. - Lifecycle of this kompositions and deployment of the Infrastructure as separate tenants. - Limitations during the maintenance of this methodology - Roadmap for the evolution of this toolset.

Join us as we discuss innovative methods designed to reduce toil within Security Operations (SecOps) at Amplify Education. First, we'll detail the use of custom security rules within Datadog, exploring Datadog's built-in scanner detection rules as well as our own methods. Then, we'll discuss a custom tool called IP Blocker that utilizes AWS Web Application Firewall (AWS WAF), Datadog, and other sources to automate blocking of IPs. Next, we'll discuss the advantages of harnessing Datadog workflows for automating a broad range of SecOps procedures, a strategy that the Amplify DevSecOps team has successfully implemented. Finally, we'll discuss some of the problems that Amplify has run into with our implementation of AWS WAF with a combination of AWS-managed and custom rules.

I will explore how an engineer can build his/her own Cloud Native Platform without losing the cool. I will take a deep dive into the realm of Platform Engineering. What is it? Is it just a buzzword? Can we learn how to build a platform in 50 minutes and demonstrate its value? Platform Engineering has become a hot topic in the tech industry. It promises to streamline operations, foster innovation, and accelerate product development. But is it just another industry fad, or is it a game-changer here to stay? Together, we will embark on an exhilarating journey to build a platform from scratch. This hands-on approach will provide attendees with practical insight into the intricacies of Platform Engineering. We'll break down the processes, discuss the tools, and navigate the best practices to construct a robust and scalable platform. By exploring the practical aspects of Platform Engineering, we aim to demystify the hype and equip participants with the knowledge and skills to leverage this emerging field effectively. Whether you\'re a seasoned pro or a curious novice, join us as we uncover the real value of Platform Engineering. Let's build, learn, and hack together, as part of a supportive and collaborative community!

Ready to observe your GitHub Actions from a central repository? At Elastic, we implemented our custom OpenTelemetry Collector receiver to collect GitHub Actions logs and combine it with the existing traces receiver to observe all workflows in our GitHub organization. Learn about the challenges we encountered, how we solved them, and see how centralized logs, traces, and metrics empower the analysis and visualization of GitHub workflows. At Elastic, we use GitHub Actions in multiple repositories for our CI/CD pipelines. However, we faced challenges with decentralized logs, which made troubleshooting issues that spanned multiple workflow runs or repositories difficult. In this session, we explain how we centralized GitHub Actions telemetry using OpenTelemetry Collector and how it helped us improve our analysis and visualization of GitHub workflows. Initially, we focused on scanning logs to detect security vulnerabilities and creating a unified platform for searching, analyzing, and visualizing logs, complete with custom alerts and notifications. As our project progressed, we realized the broader advantages of centralized logs combined with traces and metrics, which we are going to explore with real-world examples. We will examine how we handled spikes in log volume, navigated GitHub Actions API rate limits, and ensured data integrity while implementing the custom OpenTelemetry Collector receiver for GitHub Actions log collection. We planned to use OpenTelemetry Collector as the primary log receiver and exporter. To ensure reliability, we intended to queue webhook events with a proxy service, which sends them to the collector at a controlled pace and retries failed requests. We will discuss how to fine-tune the receiver for log volume efficiency and optimize the collector\'s reliability. Visualizations will showcase the impacts of various configuration changes on performance, and we will explain why we did not implement the proxy service. Finally, we will share real-world examples of how centralized logs, traces, and metrics have empowered our analysis and visualization capabilities by showcasing how we leveraged detection rules to find leaked secrets and sensitive information in logs, making identifying and remediating security vulnerabilities easier. showing how we used traces to identify bottlenecks and the most failing runs to optimize our workflows, demonstrating how centralized logs helped us identify the frequency of flaky commands and prioritize optimization and troubleshooting efforts, sharing how we crafted informational dashboards using the provided traces and metrics to help us find optimization opportunities.

Transactional infrastructure is not suited for processing large amounts of data for analytics. In this talk, participants will learn about data architecture fundamentals and get deep insights into building an enterprise-grade data lake with a business intelligence frontend on AWS, using AWS analytics services such as Glue, Athena, Lake Formation, Kinesis and QuickSight. (While the presentation is based on AWS, the fundamental concepts are transferable to other environments.)

In this talk, I'll share the lessons from a month-long journey into a production-scaled incident that degraded the quality of service in a large-scale multi-tenant, multi-region, multi-cluster Kubernetes cluster. We'll start with a seemingly innocent error and delve deeper into a series of unexpected issues affecting application performance. We'll explore the importance of Service Level Indicators (SLIs) and Service Level Objectives (SLOs) and their role in incident management. Then, I'll discuss how to leverage data, employ observability tools, and iterate on feedback loops to navigate complex issues. This talk will highlight the significance of structured incident management and a data-driven approach to ensuring system reliability.

Experienced Database Administrators (DBAs) bring invaluable expertise and historical context to DevOps endeavors. This session explores effective strategies for leveraging their knowledge, fostering collaboration, and maximizing their contributions to drive DevOps success. Discover the importance of experienced DBAs, their role in bridging the gap between traditional practices and modern DevOps methodologies, and practical approaches for inclusive environments that value their insights. · Recognizing the unique value of experienced DBAs in the DevOps landscape · Leveraging historical context and technical expertise to optimize performance and troubleshooting · Bridging the gap between traditional database practices and modern DevOps methodologies · Fostering collaboration and effective communication between DBAs and DevOps teams · Creating inclusive environments that encourage knowledge sharing and mentorship · Harnessing the technical prowess of experienced DBAs to drive informed decision-making · Nurturing a thriving DevOps culture that embraces the contributions of DBAs Join us as we explore the immense value experienced DBAs bring to DevOps and unlock their potential to drive success.

Join us as we walk you through our application of GitOps in both our Infrastructure as Code (IaC) and application delivery processes. We'll share how we've integrated ArgoCD and GitHub Actions as core components in our GitOps journey. Furthermore, we'll give you a glimpse into our microservices and multi-platform environment in Kubernetes, emphasizing security standards, such as cross-account KMS for encryption both at rest and in transit, and multi-account and multi-region operations. By the end of this talk, we hope to give you some insights and practical tips that you can apply in your own tech journey about KMS, Secret management, IRSA, mTLS, static analysis checks (tflint, trivy, etc.), helm charts, Karpenter and monorepo.

In today’s fast-paced and complex technological landscape, observability has become a critical aspect of ensuring the reliability and performance of software systems. However, traditional observability tools and techniques can only go so far in providing insights into the behavior of these systems. Enter ChatGPT, a conversational AI tool that can help bridge the gap between observability and human understanding. In this session, we will explore ChatGPT and how it could theoretically be used to enhance an enterprise’s observability practices. We will briefly look at how ChatGPT can be trained to understand and interpret system logs, metrics, and other observability data, and explore whether it can provide useful real-time insights and recommendations to engineers and operators. By attending this session, you will gain a deeper understanding of how conversational AI can be leveraged to improve observability in software systems, and how ChatGPT help you avoid potential issues before they become critical problems.

Platform teams' mission is to lay the necessary foundation for product teams to increase business value and delight customers. They do this by building platform products that ensure and accelerate high-quality delivery and operations. Very often, however, platform teams are so overwhelmed with operational workload that cannot deliver the product roadmap they promised. Recovering production, troubleshooting applications, assisting product/dev teams, managing vendors... consume nearly their entire capacity. In this talk, we will review together some Lean techniques that can help us reduce our operational load so that we can focus on building the best platform products.

One of the most important cloud computing benefits is to focus on efficiency in every aspect of our infrastructure, and builders can accelerate the sustainability of their workloads through optimization and informed architecture patterns. In this session we’ll show you practical examples that combine different techniques how to build for sustainability on Amazon EKS by making use of Graviton, EC2 Spot, effective autoscaling with Karpenter, among other topics. Our aim is to provide a direction on reducing the energy and carbon impact of cloud architectures running on Amazon EKS, that at the same time will help you to optimize for costs.

One of the emerging standards for cloud (native) security is OPA, the Open Policy Agent; an open source standard under the Cloud Native Computing Foundation. This talk gives an overview of what OPA can do for you and how you can write declarative policies to check your APIs, Kubernetes, or applications. It's structured into three segments: 1. Why do you want to add a continuous runtime checker to your APIs or applications and what gaps is it covering? 2. How do you write declarative policies with OPA? 3. What does it look like in hands-on examples against APIs, Kubernetes, and applications?

DevOps has been growing in popularity in recent years, particularly in (software) companies that want to reduce their lead time to be measured in days/weeks instead of months/years. But, what about the secrets? The current trend increases the number of secrets required to run our services. This places a new level of maintenance on our security teams. How can we share and manage the secrets (certificates, passwords, SSH, API keys) for our services in this dynamic scenario, where instances are started automatically, where there are multiple instances of the same services for scalability reasons? Are you keeping up? How are these secrets managed in GitOps? Come to this session to learn how to keep secrets secret for the whole lifecycle of the application, from the early beginning when you start developing it until the application is up and running in the Kubernetes cluster.

In this presentation we'll introduce you to k6, an open source load testing tool by Grafana Labs. k6 is easy to run, powerful and flexible thanks built-in Javascript engine. You'll learn how to define testing scenarios in Javascript, set checks for expected behavior, define thresholds and visualize testing metrics using tools like Prometheus, InfluxDB and Grafana. k6 can run distributed tests and can be controlled remotely through a CLI and API.

In this talk we show how we design and implement automation process to manage one of the most important programs in Allianz (Global Platform) in automatic way. Deployed in multiple countries, clusters and managed by different teams with full responsibility and autonomy. How we are doing cloudification strategy with our cloud providers, to manage the platform fully in cloud. We talk about APIs, Kubernetes, AWS, CI/CD, tooling and process and also about how enablement teams are supporting business teams to deliver business requirements in a quick way.

When launching new products or dealing with an outage, customer-facing teams see terms thrown around internally that customers might not identify with immediately. Good communication practices, including good translation of engineering terminology to customer-friendly communication can save time and increase customer satisfaction when moments matter. Customer Support's unique ability to understand both what is happening internally as well as what customers need to hear positions your team as the experts to steer communications during major incidents. Come to this talk to learn how to partner with your customer facing teams during major incidents.

At conferences we tend to focus on success stories, how we accomplish something, projects that are great successes and, although it’s inspirational, we forget about the failures that we find during the journey, which can be powerful sources of learning and growth. This is the story of a failure that could have been avoided. The journey was plagued with monsters such as synchronous and asynchronous communication between services, unexpected production problems, and more. We will reflect on how we tackled these challenges, and the lessons learned that shaped us for future projects. Join me on this trip about embracing failures as an integral part of success.

AI is an amazingly powerful tool that has the potential to revolutionize DevSecOps workflows. Unfortunately, it also has the potential to take over much of the important work that we currently perform. Our DevOps and SecOps teams have started experimenting with AI in several areas: - Creating an intentionally vulnerable Python program for a Capture-the-Flag class - Using our existing FAQs to create a Tier 1 Support chatbot for our software engineers - Using our incident response logs to create a predictive model to avoid future incidents - Using our AWS usage metrics to automatically generate auto-scaling policies - The use of AI log analytics to alert on security threats Our talk will demonstrate these AI interactions and will discuss the tools and techniques that we used to create these AI models. The objective is to provide the audience with a great start so they can explore AI use cases in their own organizations. We will conclude the talk with some examples of innovative use cases that we discovered while researching how AI is being used in other organizations.

Operators are extensions to Kubernetes that simplify application install and management by leveraging on Kubernetes Custom Resources and Controllers. The Kubernetes Operator pattern tries to emulate the role of a human operator, who uses their deep knowledge of the application to install, operate and debug it. The Kubernetes Operators search to automate these tasks and facilitate the whole application life cycle. Last year at DevOps Barcelona, Aurélie and Horacio showed how to build a Terraform provider, using as example an external API and lots of Gophers. This year they would like to take a similar approach to show you, step by step, how to create a Kubernetes Operator. By taking again as base the Gopher REST API, they will explain the basics of an operator creation, give some pointers on how to do a simple yet efficient operator architecture that manages not only Kubernetes objects but also resources outside Kubernetes, and show you the code and the provider in action. Will they succeed in this new mission?

Once upon a time, in the ever-expanding realm of cloud computing, a group of brave engineers embarked on a quest to protect their organization's cloud infrastructure from the perilous threat of misconfigurations. This is the story of their adventure at Datadog, where they unravel the mysteries of detecting and fixing cloud misconfigurations at scale. In this talk, we invite you to join us on this remarkable journey. We will dive into the world of security, system and software engineers running services in the cloud, as we unveil practical insights and effective strategies for addressing misconfigurations. Our story commences by shedding light on the significance of cloud misconfigurations and their potential ramifications. Through real-world anecdotes and cautionary tales, we will highlight the profound impact that misconfigurations can have on security, performance, cost and compliance in cloud environments. As our intrepid adventurers venture deeper into their mission, they uncover a plethora of tools and techniques to detect cloud misconfigurations at Datadog scale. We will delve into the realm of automated monitoring and auditing, exploring how Datadog's security team harnesses the power of intelligent checks and comprehensive scanning to swiftly identify vulnerabilities and misconfigurations. But detection alone is not enough to protect against the perils of misconfigurations. Our heroes press forward to discover the art of remediation. Through their trials and triumphs, we will unravel the secrets behind prioritizing and rectifying misconfigurations effectively. Topics covered include workflows, leveraging infrastructure-as-code principles for automated remediation, and integrating continuous integration and continuous delivery (CI/CD) pipelines to enforce best practices. Throughout this enchanting narrative, we will weave together practical examples and relatable experiences that resonate with both beginners and those seeking to enhance their cloud security knowledge. By the end of our tale, attendees will be armed with actionable insights to implement robust detection and remediation strategies in their own cloud environments. In a world where cloud services are under constant scrutiny, this talk serves as a guiding light, empowering attendees to fortify their cloud infrastructure against the ever-evolving threat landscape. So, come, embark on this extraordinary adventure and discover the story of detecting and fixing cloud misconfigurations at Datadog scale.

Authentication is scary, difficult, dangerous, and… essential. Most apps need some form of it, often as a prerequisite for almost all end-user requests. Join me for a fresh and practical perspective on authentication architecture for the modern, open web, using modern standards. We'll set up an authentication layer that's fast, distributed, secure, isolated from the rest of your system, and minimally annoying to integrate and maintain.

Communication between different parts of your distributed application can become very complex if you don’t have good architecture practices. In this session, you will learn how and when to apply two architectural patterns in your distributed applications: orchestration and choreography. In addition, you will learn how to orchestrate complex workflows with state machines and how an event bus can help you choreograph micro services. And you will also get good practices on how to use them to make your application scale and be maintainable.

Currently when we think of Infrastructure as Code (IaC), one tool seems to stand out and has become a de-facto standard: Terraform. With Terraform you can easily build, edit and version your whole infrastructure by using Terraform builtin providers or custom ones. But sometimes there is no provider for the infrastructure you intend to use, not even the lone no-star repository in a lost corner of the internet, only a custom REST API. What can you do? Going back to manual operations? Create your own scripts? In this talk Horacio and Aurélie will show you, step by step, how to go from an infrastructure API to a fully functional yet light Terraform provider. By taking as base a REST API, they will explain the basics of provider creation, give some pointers on how to do a simple yet efficient provider architecture and show you the code and the provider in action. Will they succeed in this new mission?

My team and I are SREs and run one of the most important service stacks at Google: authentication. Our role is to make our services reliable and secure through engineering projects. But we sometimes fail, even if our SLO can be as high as 99.9999% uptime (31.56 seconds downtime per year) in some cases. Whenever our services are down, mostly every Google product is down, our billions of customers can't access their own data they have entrusted us with and you make it quickly through the press. Business across the globe can be affected. When you are oncall and get one of the pages that makes you think "oh gosh", what really happens behind the scenes? How to go from a potentially cryptic alert message to a full blown incident response team coordinating over tens of engineers? After mitigation, the complete repair starts and the forensics style root cause analysis needs to indicate what happened and how to prevent that failure class forever. We also need to travel back in time: outages do not randomly happen, but have a trigger in a broken process, a system interaction, a small code piece. In this talk, we'll go through the beautiful process of failure and recovery, examining real outages that have affected hundreds of millions of customers and seeing what happened, how we approached it and what we learned. We'll deep dive on some of the responses and how can the be exported to other organisations. We'll learn how our organisation has evolved to be resilient as well, over the last 15 years of operating systems at hyper-scale.

The hotels Network decided to move from a batch processing analytics platform to a real time analytics platform based on a services architecture. To accomplish this, we decided to look for kafka solutions (finally decided to go with Redpanda) and found we needed to add ksqlDB to our architecture. We will share what drove us here, the key decisions, the mistakes we made, the goals we achieved... It might not be exactly your case, but sure you can benefit from some of our findings

This talk will show how important it is to onboard network engineers on the DevOps culture as one of the pillars of the DevOps transformation. Traditionally, network operations have been seen as close silos where everything moved slowly and with few (or none) visibility from the applications or systems engineering side, and it’s also true that their evolution into the DevOps principles has taken more than on the system administration, but the good news are that in 2022, most of these teams have closed the gap and are now key players on delivering IT services, adding a lot of value with them. We can’t forget that, in a lot of cases, we sustain our applications on hybrid deployments running on complex network architectures, with multiple layers of abstraction, starting from the “real” IP network, passing over several overlays (does K8S sound familiar?) and, finally, the service mesh. Including network engineering knowledge in this endeavour will help understanding and optimising these architectures, enforcing consistent IP address management and consolidating more metrics to enrich your observability system. In this session you will understand how to make this transformation possible and identify relevant skills and tooling that a network engineer has to adopt to jump on this boat.

Tracing and telemetry are popular topics right now, but the development is so quick that it also confuses: Starting with OpenTracing, then W3C Trace-Context, and now OpenTelemetry there are plenty of standards, but what do or don't they cover? With tracing being stable, how are the metric and log efforts going in OpenTelemetry? Where is OpenTelemetry headed as a project, and how can both users run it in combination with their vendor of choice? This talk gives an overview of standards, projects, and how they all tie together.

Container technologies, although not new, have increased their popularity in the past few years, with container orchestrators allowing companies around the world to adopt these technologies to help them ship and scale microservices with precision and velocity. Kubernetes is currently the most popular container orchestration platform nowadays, and the one chosen by Datadog to run its infrastructure. We run dozens of clusters, with thousands of nodes, and we run them on different public clouds. How are our +1K engineers able to use this infrastructure platform successfully? Join me in this talk for our story on what we learned while we scaled our Kubernetes clusters, the contributions to Kubernetes we made along the way, how we are building a development platform around it, and how you can apply those learnings when growing your Kubernetes clusters from a handful to hundreds or thousands of nodes.

In this session we will address best practices to effectively implement Zero Trust architectures within our organization, this will allow us to reduce risk in all environments by establishing strong identity verification, validating device compliance before granting access and ensuring least privilege access only to explicitly authorized resources. We will discuss how through the services Azure offers us, using Azure for Zero guardrails and blueprints to implement it and focusing primarily on identities, devices, applications, data, infrastructure and networks, helping us increase the speed with which cloud-based initiatives achieve authorization is a critical part of modernization.

Choosing the right open-source project to use can be quite challenging - not knowing if it’s going to be the right fit, how it will behave, and if you end up wasting time trying to make it all work. We’ve all been there. But what if I told you there’s a practical way to have a clear understanding of how to incorporate an OSS project in your environment? In this talk, I’m going to speak about the DevOps perspective on open-source and the challenges Infra-focused engineers have with choosing the right project for their environment. As a DevOps Engineer, I’ve seen a lot of things, stumbled upon a lot of non-based decisions, and so will present practical advice on how to choose an OSS project for your dev/prod environment and will talk about the business mindset you should have to evaluate the key indicators based on your needs and specific pain points.

DevOps engineers tend to be obsessed with their favorite tools and platforms. That could be Docker, Kubernetes, Terraform, Prometheus, Grafana, Crossplane, or any other among miriad of those labeled as "DevOps". However, that is often missing the point of what we're trying to accomplish. The goal should be to enable everyone to be in full control of their applications, including dependent services and infrastructure. DevOps is about having self-sufficient teams and the only way to accomplish that is by providing services that everyone can consume. Instead of waiting for requests to create a cluster, perform security scanning, deploy an application, and so on, ops and other specialized teams should be enabling others to do those operations. That enablement is best accomplished by creating an Internal Developer Platform (IDP). In this session, we'll explore the architecture and the key ingredients needed for an IDP. We'll also discuss the key benefits of an IDP and we'll see, through a demo, how we could build one. We'll combine tools like Backstage, Argo CD, Crossplane, and quite a few others into a platform that everyone can use, no matter their experience level.

13 years ago we had the idea to organise a conference in Gent to bridge the gap between developers and the people runing their code. It was the start of a new global movement. We never predicted that #devops would be where #devops is today. The word devops has evolved, the community has evolved. Docker has solved all of our problems, the ones left behind were solved by Kubernetes. Everybody and their neighbour is Scrum certified now and we are all happily sipping cocktails on the beach. Or not? Why after almost 10 years of pushing culture change, teaching about Infrastructure as Code, teaching about Monitoring and Metrics … and help people to share both their pain and their learnings are most organisations still struggling with software delivery. Over the years the word devops lost it’s meaning at least it’s original meaning. The real challenge for the next decade will be to see how we can revive those original values and ideas, if at all... Can we fix Devops ? This talk will give you some Ideas about that.

A presentation on how GitHub builds and deploys software and the pillars upon which those development and delivery practices are built. This talk will provide some insights into the challenges and complexities in having a globally distributed workforce, providing abilities for developers to collaborate, innovate and experiment safely, ensure compliance and security and ship changes reliably to production systems.

Zero trust security is predicated on securing everything based on trusted identities. Machine authentication and authorization, machine-to-machine access, human authentication and authorization, and human-to-machine access are the four foundational categories for identity-driven controls and zero trust security. The transition from traditional on-premises datacenters and environments to dynamic, cloud infrastructure is complex and introduces new challenges for enterprise security. This shift requires a different approach to security, a different trust model. One that trusts nothing and authenticates and authorizes everything. Because of the highly dynamic environment, organizations talk about a "zero trust" approach to cloud security. What does “zero trust” actually mean and what’s required for you to make it successful? Attend this session and you’ll learn from Armon Dadgar, HashiCorp founder and CTO how your organization can enable scalable, dynamic security across clouds.

Copy and paste of Terraform reduce reusability, maintainability, and scalability of our configuration. In an effort not to repeat ourselves, we might start moving our configuration into modules and run into new scaling and collaboration challenges! In this talk, I will describe some of the challenges and lessons learned in building, scaling, and maintaining the public Terraform modules for AWS components and how to apply them to your modules. I defined an initial goal for those modules to provide a powerful and flexible way to manage infrastructure on AWS but with more than a couple thousand issues and pull-requests opened since the beginning, the goal had to change. What started as an initial set of basic Terraform AWS modules for common architectural patterns on AWS soon became a base for many customers using Terraform and required radical changes and improvements. I will describe some of the challenges along the way and lessons learned when building entirely open-source Terraform modules used by thousands of developers. Some problems are technical such as versioning, quality assurance, documentation, compatibility promises, and upgrading. Other problems are around collaboration and software design principles, such as how to reason about feature-requests or how small should a module be. I will also examine the testing strategy for terraform-aws-modules and discuss the reasoning for not having tests! I will provide a list of dos and don’ts for Terraform modules that highlight the critical features (e.g., documentation, feature-rich, sane defaults, examples, etc.), which make terraform-aws-modules scalable in collaboration and use. By the end of the talk, attendees will understand proven practices around building useful, maintainable, and scalable modules, learn about public modules available to them, and how they can participate in making those open-source projects better.

Over the past few years, CDNs have evolved into sophisticated edge cloud platforms with focus on flexibility, programmability, functionality, and security. But it's been a path easier said than done. In this session, we'll discuss this transformation, how the core building blocks remain vitally important, and how properly built edge cloud platforms offer brand new ways for scaling applications well beyond just content distribution.

Intelligent models often work very well in laboratory or "controlled" datasets but when it comes to testing them with big, real world, datasets we often suffer from some lack of maturity in the technical side of things: we need infrastructure, QA processes, automation pipelines, constant data ingestion, deploy evolutions of the model ... to name a few. In this talk we will discuss MLOps (what it is, why we need multiple software development profiles...), where are the most common bottlenecks and some open-source initiatives to ease the "go to production" phase such as Gradio's Hugging Face, Streamlit or Kubeflow.

At N26, we want to make sure we have resilience and fault tolerance built into our backend service-to-service calls. Our services used a combination of Hystrix, Retrofit, Retryer, and other tools to achieve this goal. However, Netflix recently announced that Hystrix is no longer under active development. Therefore, we needed to come up with a replacement solution that maintains the same level of functionality. Since Hystrix provided a big portion of our http client resilience (including circuit breaking, connection thread pool thresholds, easy to add fallbacks, response caching, etc.), we used this announcement as a good opportunity to revisit our entire http client resilience stack. We wanted to find a solution that consolidated our fragmented tooling into an easy-to-use and consistent approach. This talk will share the approach we are currently implementing and the tools we analyzed while making the decision. Its aim is to provide backend devs (primarily working on JVM languages) and SREs with a comprehensive view on the state of the art for service-to-service call tooling (resilience 4j, envoy, gRPC, retrofit, etc), mechanisms to improve service-to-service call resiliency (timeouts, circuit breaking, adaptive concurrency limits, outlier detection, rate limiting, etc.) and a discussion on where these mechanisms should be implemented (client side, side-car proxy, server-side side-car proxy or server-side).

Tired of wrapping pickled models in server logic? me too! The biggest bottleneck in delivering machine learning services is the handover from data science to engineering. Providing scientists with a predicable and safe way to deploy their own models will decouple the engineering and data science efforts allowing each departments to focus on delivering value instead of completing repetitive tasks. This was achieved by exposing a pub/sub interface where data models just have to register as services and they are automatically exposed to the rest of the organisation.

Most organizations feel the need to centralize their logs — once you have more than a couple of servers or containers, SSH and tail will not serve you well any more. However, the common question or struggle is how to achieve that. This talk presents multiple approaches and patterns with their advantages and disadvantages, so you can pick the one that fits your organization best: * Parse: Take the log files of your applications and extract the relevant pieces of information. * Send: Add a log appender to send out your events directly without persisting them to a log file. * Structure: Write your events in a structured file, which you can then centralize. * Containerize: Keep track of short lived containers and configure their logging correctly. * Orchestrate: Stay on top of your logs even when services are short lived and dynamically allocated on Kubernetes. Each pattern has its own demo with the open source Elastic Stack (previously called ELK Stack), so you can easily try out the different approaches in your environment. Though the general patterns are applicable with any centralized logging system.

Operating a complex distributed system such as Apache Kafka could be a lot of work, so many moving parts need to be understood when something wrong happens. With brokers, partitions, leaders, consumers, producers, offsets, consumer groups, etc, and security, managing Apache Kafka can be challenging. From managing consistency, numbers of partitions, understanding under replicated partitions, to the challenges of setting up security, and others, in this talk we will review common issues, and mitigation strategies, seen from the trenches helping teams around the globe with their Kafka infrastructure. By the end of this talk you will have a collection of strategies to detect and prevent common issues with Apache Kafka, in a nutshell more peace and nights of sleep for you, more happiness for your users, the best case scenario.

Data drives us, this is one of the most used mottos among all the organizations. Most of us would like to make our decisions data-driven. That will give us more confidence about what what we have decided. This is not always easy. It’s even worse when a bunch of people needs to agree on the decision. Because each of them may bring their own data. Comparing apples to oranges is challenging at best and at worst really hard. Latency Map was born to help the business to make better decisions, bringing latency metrics to the stage. If you achieve that these data become the source of truth, you nail it. This is the first step to stop neverending discussions about if that measurement is better or worst than mine. At Adevinta, we have used Latency Map to decide on the best cloud regions to deploy our services while minimising end customer latency. We’ll be glad to share our journey, including the tech stack we used, options we dismissed, lessons learnt, and some actual findings from the latency-measurement data we are collecting. The journey that allowed us to come up with a complete product, and how the outcome, actual latency data, may help you to make the best decisions in your trip to the Cloud.

What's all this fuzz about ethics? And why should we care? In the fastest-paced environments, where we're asked to deliver features as quickly as we can think of them, it's not easy to take a step back, stop for a minute and pause to consider the ethical implications of what we're doing. Yet, consciousness about these concerns is growing lately. Let's explore what we can expect to get from it, and why we would go down this road of endless questions and very few answers.

In a perfect world we would run monolithic systems on machines with unlimited CPU, Memory, Disk and Network IO, and with 100% reliability. The reality is that such a machine does not exist, and to deliver the demands of performance and availability our users demand from our systems, we have to be creative in partitioning workload over multiple machines, geographic regions, and failure domains. This approach introduces complexity to our systems, we expect failure and design accordingly. In this talk, Nic will walk through the areas of complexity in a system we will then look at what patterns you can employ to ensure performance and availability even in a failing world. This demo-driven talk will showcase the patterns that can help to adopt a distributed architecture for your applications, especially when moving from a monolithic architecture to a distributed one.

In any Cloud Native architecture there’s a seemingly endless stream of events that happen at each layer. These events can be used to detect abnormal activity and possible security incidents, as well as providing an audit trail of activity. In this talk we’ll cover how we extended Falco to ingest events beyond just host system calls, such as Kubernetes audit events or even application level events. We will also show how to create Falco rules to detect behaviors in these new event streams. We show how we implemented Kubernetes audit events in Falco, and how to configure the event stream. Finally, we will cover how to create additional event streams leveraging the generic implementation Falco provides. Attendees will gain deep understanding of Falco’s architecture, and how it custom Falco for additional events sources.

DevOps and Agile are great at speeding up development and providing quick results, however most organisations struggle to transition and adapt their team and leadership structures, which is made of FAIL. In this talk I'll go through some of the experiences I had and interesting ways to solve it while keeping it light so you don't have to run for coffee.

Kubernetes has become the standard tool to deploy applications both in Cloud and on premise datacenters. This has been possible thanks to its powerful API and its model that allows us to describe the lifecycle of an application. In this talk we are going to explain how Kubernetes works internally, showing what Kubernetes controllers are and how they work. Once we understand that, we will learn how we can extend the features that Kubernetes already offers to tailor it to our needs, and how big companies are investing on projects and tools that are based on this mechanism.

Kubernetes based PaaS are becoming more and more popular in the Enterprise. This means large enterprises need to accommodate to and integrate the new paradigms into their current non-agile (and very often ITIL-based) operational model. DevOps can help traditional IT operational groups make a smooth transition. In this process, automation technologies need to be considered to provide an automation API for every group and also, very important, to help clarify the chain of responsibility and improve traceability. The goal of the session is to provide an overview of a modern cloud operational model for Kubernetes in a complex scenario. We will introduce Ansible as the automation key technology to provide an API for every context of the model and show how we can implement a Kubernetes life-cycle on OpenShift. And finally, we will also discuss how this can still match the ITIL operational model.

Mobile app releases are a manual, tedious and error-prone process when done at scale. It is not possible to follow a continuous delivery (CD) approach because binaries need to be submitted to the stores, and once published they can’t be rolled back. Moreover, mobile releases can take several days to complete. In contrast, we deploy the web version of Shopify around 50 times a day. We identified this gap between web and mobile releases as a problem. In this talk, I’ll explain how my team built a continuous integration (CI) system for our mobile apps (Android and iOS), and how we used this infrastructure as a foundation to build a Ruby on Rails application and other tools to automate and orchestrate releases to Google Play and the App Store, reducing the need for human interaction as much as possible. We’ll see the challenges of standardizing the release process and the coordination with third-party services like GitHub and the store APIs, and how we made it easier for developers to test the apps.

DevOps is growing in popularity in last years, particularly in (software) companies that want to reduce its lead time (time to business value from idea to production) measured in days/weeks instead of months/years? If you want your software to do the right things and do these things right, you need to test it implacably. The big problem is that companies see (and it is) the testing phase as the bottleneck of the process slowing down product release. To change that, we need a new way of testing our applications, making the release of an application a testing process as well, and involve QA since the beginning within the team. QAs are not a separate team anymore (DevTestOps). What is the role of QAs in this new approach? How is the testing pyramid affected? How you can fail on trying to speed up release frequency? In this session, we will not only describe but also actively demonstrate several techniques that you can use immediately following the session for testing applications like unicorns.

In this talk i will explain how to integrate a Jmeter in your continuous integration system. I will demo how to create a stack with grafana, influxdb and jmeter in docker to show in real time results. And how to create more legible tests thanks to blazemeter taurus in a yaml format.

Elevator Pitch With an investment 4.1bn in boot technology, I want to tell you about the awesome innovations Nationwide Building Society UK have made and challenges we have overcome as a financial services institution, applying DevOps the right way, building a cloud platform. But wait! Let’s make it raw, I’ll tell you about the pain, the politics, huge consumers of K8s & ChatOps pus find out how we made a trading card game for the office the ended up driving some phenomenal behaviours! Why do almost all of our platform engineers write code. Longer Pitch Nationwide Building Society UK has invested 4.1bn in the future of technology for the society, cloud is a sensitive word when you’re a financial services organisation, it’s even more delicate when you’re regulated by the Financial Services Authority and the Prudential Regulation Authority. I would love to tell you the story of how one of the most risk adverse fs institutions navigated cloud adoption, the technologies we have used and how, including kubernetes. Everyone has a heard of the Spotify model, if one thing is clear, you shouldn’t adopt it, let me tell you about how we took agile to the next level, what was right for us at our scale, maturity. How does a trading card game have anything to do with agile or operating a cloud platform at scale, I don’t want to give everything away just yet but you should listen to the talk and think about giving it a shot your self. ChatOps has been a huge technology enabler for us, I’l talk you through some of the stuff we’ve built into our bot such as automatic postmtportems and diary management, dashboards at a glance, how we automated our ingress kill mechanism and used the Shamir algorithm to distribute the key. How do we organise our squads, demand flow, ensure we’re delivery, why scum didn’t work for us and why kanban make much more sense. How we built, chat-op’ed the hell out of the on-call rota using twilio and slack! Demo!!! Observability, nice as a concept but how did we drive adoption when we’re a platform, DevOps Dojos! Why do we encourage our engineers to take a couple of days out a month to teach! We have a lot to cover but I’m sure you will find this insightful and interesting, fs orgs usually move like frozen snails and we’re dancing like matrix neo on a red pill. ChatOps demo’s included, they are pretty quick which makes them excellent demos and seeds of inspiration.

Gone are the days of hand-typing commands into network devices one by one: the same benefits of Ansible seen on compute nodes can now be extended to the network nodes. Through automation, CI/CD is not an application development concept anymore, but an enterprise culture that can also be extended to the network discipline. Learn about the difference between traditional and next-gen network operations, and why network teams need automation.

In this talk, we show the audience how we combined our experience as an enterprise SaaS provider with our experience as an OpenShift IaaS provider, to create an easy to use, easy to update and easy to rollback `Infrastructure as Code` Toolchain/Monitoring solution. This solution faces updating, misconfiguration and diversification issues, by using Docker Images in combination with OpenShift. We further discuss our self-service system, which enables us to decrease maintenance and to avoid manual steps by using automated deployment of large amounts of instances. We will then discuss the idea of saving all configuration inside version control, while totally ignoring the users' UI changes.

Machine-learning systems have become increasingly prevalent in commodity software systems. They are used through cloud-based APIs or embedded through software libraries. However, even ML systems just look like another data pipeline, they make systems sensible and might put systems health at risk without the proper control. Through discussions with engineers engaged in deploying and operating ML systems, we arrived at a set of principles and best practices. These include from input-data validation, for fairness/quality on training; contextual alerting, deployment and rollback policies to privacy and ethics . We discuss how these practices fit in with established SRE practices, and how ML requires novel approaches in some cases. We look at a few specific cases where ML-based systems did not behave as did traditional systems, and examine the outcomes in light of our recommended best practices.

You might be asking yourself why would you migrate in the first place? I will answer that in a bit, first let’s talk briefly about the cloud. Since the advent of the "cloud" and with the rise of multiple players on this space (Azure, Google Cloud, AWS), tools have made their appearance too. Tooling is indispensable for automation and automation is fundamental for scaling. Tooling will also allow you to do something else: avoiding vendor lock in in favor of a more flexible concept: cost of migration. You can apply this very same concept when you are not as advanced or working with a minor or mid-sized player in the cloud providers arena, and give you the possibility to move to another provider that better suits your needs. Why would you migrate? There could be several reasons: cost saving, service level and in our case, lack of tooling. In this talk I’ll cover a one and a half year journey at Packlink, where we migrated from cloud provider and in the way went from: · Not knowing how many servers were running · Snowflake servers everywhere · No automation · Multiple monitoring tools and no real view of what was going on To: · Exact count of resources · All the infrastructure mapped in Ansible roles · Fully automated instances creation (Hashicorp’s Terraform) and provisioning (Ansible) · Trusted monitoring and alerts (Uchiwa, New Relic, Slack) · Infrastructure as code mindset Letting you know about the problems we found, solutions implemented and tradeoffs took.

At Giant Swarm, we have been running Kubernetes clusters for enterprises for more than two years. Our approach is leveraging the Kubernetes philosophy to control the entire lifecycle of our managed clusters. We have built a control plane cluster, which takes care of maintaining the tenant clusters in the state our users have defined. In this talk, I will go through the key components of our design and how we apply DevOps practices to deliver value fast in a highly dynamic environment.

What to do when you must monitor the whole infrastructure of the biggest European hosting and cloud provider? How to choose a tool when the most used ones fail to scale to your needs? How to build an Metrics platform to unify, conciliate and replace years of fragmented legacy partial solutions? In this talk we will relate our experience building and maintaining OVH Metrics, the platform used to monitor all OVH infrastructure. We needed to go to places where most monitoring solutions hadn’t gone before, it needed to operate at the scale of the biggest European hosting and cloud providers: 27 data centers, more than 300k servers (bare metal!), and hundreds of products to fulfill our mission to host 1.3 million customers. You will hear about time series, about open source solutions pushed to the limit, about HBase clusters operated at the extreme, and how about a small team leveraged the power of a handful of open source solution and lots of coding glue to build one of the most performant monitoring solutions ever.

Have you ever heard of: 'one apple a day keeps the doctor away'? Fact that makes each one of us responsible for doing a small action that should improve our life. If we took this to the DevOps world, the proverb would be brought by DevSecOps. It adds security to the process and shifts security from reactive to proactive. Makes each team member responsible for the security of the development, the platform and the deployment, in short, of the entire product. To eat an apple would be way too easy, and that’s not what we are here for, not to be conformist, though we are adaptable we are ready to take action based on these next terms: * Teams: everyone is responsible, we must break down the barriers between us, no more traditional silos of expertise, build and deploy with security is everyone's concern. * Process: teamwork is encouraged, never hearing again: “that’s not my problem” * Technology: we need to fight against technical security debt because that’s the ballot paper we be in the news. To sum it all up, security sets the requirements and DevOps manages the frequency of scan occurrences according to the development practices. Will see how to assess the level of maturity of our organization, what metrics should we review and which are the warning signs before is too late for an ‘apple a day’ or our company makes the front page.

It seems clear to everyone that availability and performance are the main concerns when monitoring a platform. But... what happens if suddenly you discover that you were hacked some weeks ago and you have intruders on your servers? It has been always scary, from long time ago, but now it might affect personal data and the GDPR fine can be much more than "scary". Do not ask "if" your servers can be hacked, ask "when" will happen instead. And my question is... how long will it take you to get notice that you are being or were hacked? In this talk we want to show the architecture we have in place to monitor several different platforms from several different websites (such as Infojobs, Fotocasa, Milanuncios, Vibbo...), with distributed teams, diverse technologies, using a pragmatic approach for investing a very reasonable effort and money. We will explain the options when using an opensource but mature component such as ossec, combined with commercial software such as Splunk, heavily optimizing the costs. We will also approach the components that AWS provides to detect attacks and intrusions, both the success cases as the not-so-successful ones. We will address monitoring live HTTP requests, log analysis, intrusion detection on servers and also on the network. Our global approach: monitor good-quality events, not gathering big quantity of "simple" logs. All this with an expense lower than 1K per month, monitoring platforms with millions of monthly users. So it can work for both big and small pockets!

Transitioning a monolith to distributed microservices in the cloud is an excruciating process. A stateless API Gateway can help you preserve your existing API contract while developers chop the monolith in different microservices, and publish the new specification transparently. KrakenD API Gateway is a well-tested open source software with no external dependencies or moving pieces. A cluster will facilitate a journey to cloud and microservices without any supporting databases or single points of failure. The API Gateway integration with Prometheus, Jaeger, Zipkin and other logging, metrics, and tracing systems will keep the system behavior observable at all times. During this presentation, we are going to discover the architecture behind this design, how to create the endpoints in a declarative way (no coding), and HORROR STORIES!

Nowadays, startups, medium-sized companies and even big companies try to follow DevOps path. For startups and medium-sized companies, this transformation is relatively easy by comparison with well-established company. Turkcell is the leading TELCO in Turkey who has begun to work agile, so DevOps insight was inevitable. In our speak, we will try to put across our feelings to the audience by telling about 7 steps which we experienced. 1) How did the need reveal? We will try to explain the factors which forced us to think about DevOps. 2) How we decided how we start? We could choose all out transformation, but we chose two applications as pilots, since it was hard to reserve resources for applying DevOps while we must continue to production. 3) What factors did we think while we were choosing applications as pilots? We chose a service-based application and a front face application to experience differently. 4) What happened in process of building Devops pipeline? We examined what we do. How do we handle test and deployment issues within Waterfall methodology ? We used DevOps method to solve bottlenecks of deployment and testing. 5) Test Automation? We use UFT and Selenium as Test Automation tools. We focused especially front-end testing and we integrated 6 front-end application for test automation. 6) Challenges? Slowness of decision making for the big enterprises was a huge challenge. Also, since we were working in MARKETING SOLUTIONS domain, there was huge demand for business needs, we had to carry out both regular developments and DevOps initiatives with same amount of resources. 7) How much effort we spent? What were our KPIs? What are we planning to do in future, how we use lessons learned in this journey?

We will share how the Skyscanner Security Engineering team have created a service to make sense of what's going on in a highly distributed microservices environment. By gathering data from a variety of security and internal tools, and mapping it across the multiple teams throughout the organisation, we can more effectively understand the security posture of our services, allowing us to take decisions based on the risks discovered. We will cover the challenges, our road to building this solution, and the future goals.

We do love technology, don’t we? Great infrastructure and tooling take cloud adoption and mobile app development to new heights. By deeply integrating DevOps paradigms into everything, technology makes it easier than ever to build, deploy, and manage software across clouds and on-premises. The promises of DevOps are not fulfilled by technology alone. Its adoption can only be successful if organizations nail all three aspects of DevOps: People, Process, and Technology. Over the course of 5 years my team has been involved in 100s of customer and partner engagements, working hands-on with entities of all sizes from small startups to large enterprises. We worked on ways to improve the flow of value in their software lifecycle, helping them to become better and faster sooner through DevOps practices. We have learned at least as much as we taught. This session takes deeper look at the intersection of technology and people in a DevOps world and summarizes our diverse hands-on experiences with the cultural and social aspects of a DevOps adoption.

This presentation wants to share how the Skyscanner Security Engineering team have integrated security into our continuous integration and delivery (CI/CD) pipeline. Skyscanner's microservice architecture is a highly distributed and constantly changing environment supported by Kubernetes and Amazon ECS. Furthermore, Skyscanner has strong lean and agile principles, which imposes fast-paced delivery along with integrated learning cycles and decentralized decision-making. This challenges security that must shift left and become more integrated with the CI/CD pipeline without becoming a blocker.

For nearly a decade, Chef Software has been helping companies big and small automate themselves into more flexible, agile, responsive organizations. This talk will highlight the lessons we've learned, that you can learn too! to automate not only infrastructure but also security and compliance with tools like InSpec, and build and deploy with tools like Habitat. We'll look at the challenges and benefits of providing integrated workflows to help all of your teams meet their requirements in an efficient and safe manner.

Building your infrastructure in baremetal servers is a very interesting and cost-effective option, especially in these container period where we can leverage the power of orchestrators like kubernetes. Baremetal is of course less flexible and it comes with tasks long forgotten in our cloud-based days: booting management and configuration. CoreOS is a good and popular choice as a base OS for a container-based system. It is also interesting due to the tools it has to make booting and OS configuration a much simpler task. In this talk I'm going to describe two of them: Matchbox and Ignition and how we can integrate them in our Terraform infrastructure description using specific providers for it. This is part of a general approach towards immutable infrastructure provisioning.

Managing infrastructure as artifacts of code, instead of hardware, is key to scaling software organizations. Cloud APIs and automation tools can bring many techniques from software engineering to platform operation, including version control, automated testing, configuration management and reliable duplication. Programmable infrastructure becomes invaluable as organizations and applications scale and decomposes. Automating the provisioning, configuration and deployment of complex applications requires some design choices on top of AWS services. Specifically, when some resources are shared among tenants, such as databases, and others dedicated, such as distributions, these automations can become quite complex. Learn how to automate complex multi-tenant applications using CloudFormation and other tools from Amazon Web Services.

Not so long ago, in the monolithic applications era it was relatively easy to setup development and integration environments. You just need to run your application and start working on it. Nowadays, with tons of different cloud services and the microservices approach for the applications, providing and maintaining many development and integration environments for developers, QA or designers could be nightmare. Not only because of the multiple processes you have to span, but also because of the more than ever usage of cloud managed services. In this talk, we'll show you our proposal on how to provision ephemeral and dynamic development / integration environments that make use of cloud managed services with Kubernetes.

Microservices architecture has changed how companies develop and deploy applications. This change has affected testing process as well. New techniques have emerged and others have been enhanced. Come to this session to learn about service virtualization, contract testing, smart testing or testing in production to increase deployment velocity from 1 week to N times per day or deploy each service independently without worrying about breaking the compatibility between services anymore.
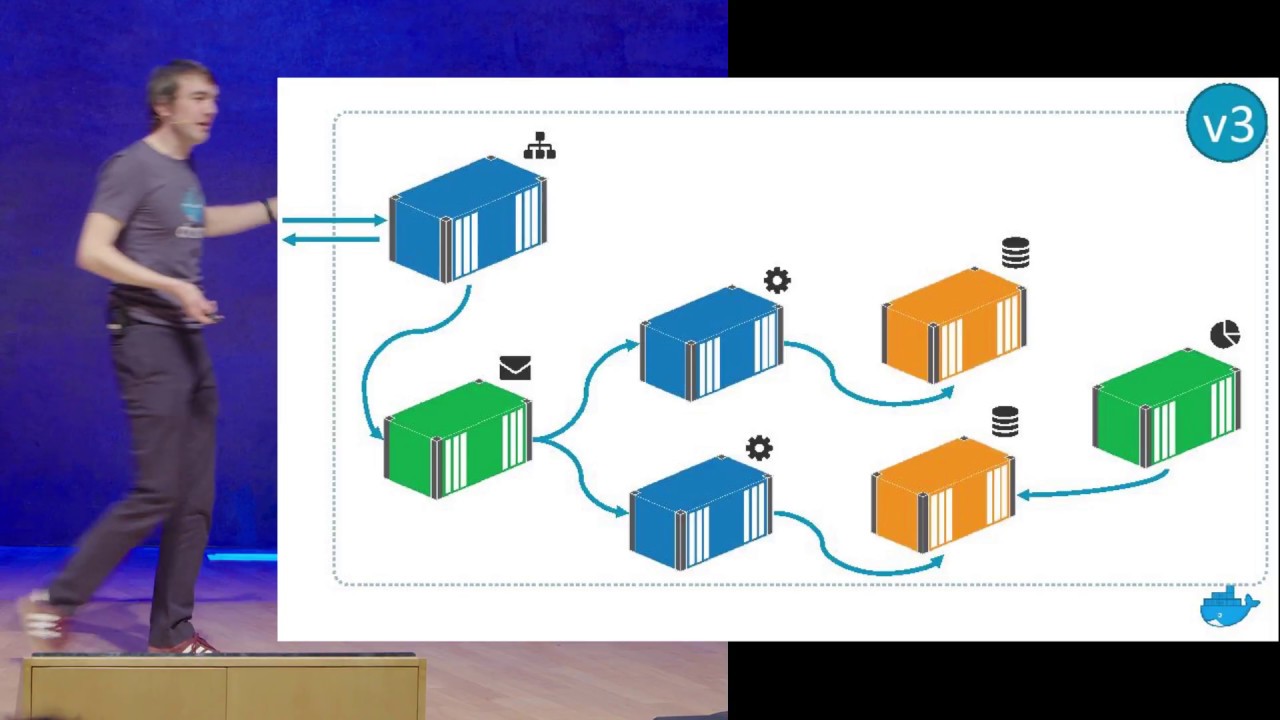
Containers are the next model of compute, after VMs and bare metal. And you all know containers are here to stay. They're the leaner, faster and more portable alternative, and one day every app will run in a container. Containers will be ubiquitous because of the wide range of problems they solve, and the huge ecosystem that's making the solutions. The core concepts in container platforms are all open - the image and runtime specifications, the registry, the engines and the orchestrators. The promise of portability makes containers a safe choice for the next generation of software delivery. Companies are making that choice and investing in containers for everything from legacy apps to new cloud-native projects. In this session I'll demonstrate two of the main uses cases for containers - moving existing apps to the cloud, and building apps in lean, modern technology stacks. I'll take an existing ASP.NET 3.5 WebForms app from a Windows Server 2003 VM, migrate it to Docker with no code changes, and then run it in Azure. Then I'll deploy a brand-new .NET Core Web API running on Nano Server in a container alongside the WebForms app.

When recruiting and onboarding new grads and others who haven't worked in site reliability, how do we build (and become) the engineers we want to work with? While seasoned engineers debug, fix issues in production, engage with clients, automate mundane tasks, and build new tools to streamline their workflows, in school new grads are mostly only taught how to build things from scratch - not support, maintain, and protect them. In this talk, I'll share my experience and describe how Facebook has made me bring ideas and people together, not only to realize my potential, but also to make a difference at the company. New grads have to be able to “drink from the firehose” of new information, learn by doing, and make connections throughout the company. On top of that, there's also the Production Engineering role and philosophy which has learned to embrace and grow people who haven't done exactly this type of work before. At Facebook, the goal is to have impact, while doing the things we enjoy. Connecting those two dots is the key.

In this talk I will cover lessons learnt when building a distributed team to deliver an infrastructure capable of handling several billion requests per month across the world. We will discuss fostering Engineering Mentality, Agile Teamwork, Scalable Knowledge and User Focus in a team. Focus will be in the DevOps and Infrastructure domains, but most content can be applied in areas like application development. Expect examples, challenges, questions, plenty of puzzlement and practical advice to survive the team building experience.

Kubernetes is changing the way we manage our infrastructures, even in big traditional companies. In everis, we are using OpenShift, the "enterprise kubernetes" brand from RedHat and Docker as an enterprise-wide development and continuous delivery platform. During this talk, I will talk about the path we started two years ago, our successes and our mistakes, on the journey to cloud-based development. we will also have a bit in-depth of the OpenShift tools that make it the perfect CI/CD platform.

Mesos has a two-level scheduler architecture. Mesos handles low-level infrastructure scheduling operations, while another layer on top (The frameworks) handles all the application specific operations and logic. In this talk, we will discuss the pros and cons of having separate layers. And limitations caused by the gap between development cycles of both layers.

Creating a software development Value Stream Map is an exercise to identify delays caused by people, processes and tools. We have been running DevOps focused "hackfests" with customers. Prior to each event we meet to create a Value Stream Map of the software development processes. In addition to improving understanding of the existing state the exercise enables opportunities for improvement to be identified. Given the fact engagements only last for a few days they have been vital in pinpointing which DevOps practices we should focus our effort. The Value Stream Mapping process has not just been useful for the hackfest but has proved to be an extremely valuable process for all involved. The value stream mapping exercise wasn't just useful in terms of laying out the technologies and processes. It was also a bit of a trust and familiarisation exercise for the teams and individuals. We found it extremely valuable. Isolating and realising how much ‘waste’ there was really interesting to me. I knew there was quite a lot but identifying exactly where and how much there was essentially gave us a green light to carry our further work to improve our build system. During the session I will describe Value Stream Mapping and the process we carry out. I will then present a number of real world case studies and discuss some of the more interesting areas of waste that we have been able to identify.
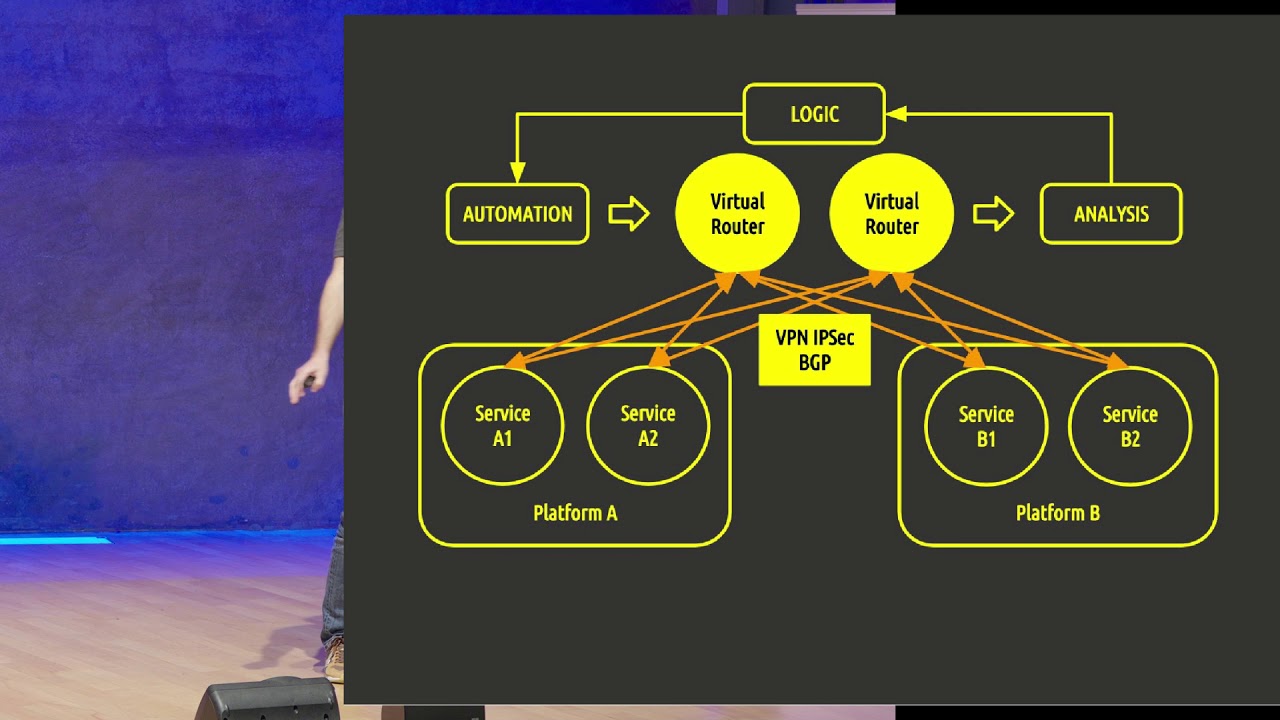
I will show how Schibsted as an heterogenous company with services on-premises and in several Public Clouds is creating a global network to enable service to service private communication across all our platforms will extend the scope of global services and also increasing efficiency by consolidating towards a common hybrid infrastructure while automating and abstracting networking tasks. The talk will have a general introduction to the problem, the suggested architecture and the tooling to make it possible following a DevOps approach.

With the physical data center we used a Castle & Moat approach based on networking, but in the cloud, we have no clear perimeter and need to take an application-centric approach to security. This talk examines the areas of vulnerability inside a typical microservice application, areas like authentication and authorization, secrets management, and credential management. We examine these problems from an operational perspective and how we can solve them by leveraging the power of Vault, an open-source tool from HashiCorp.

"With microservices every outage is like a murder mystery" is a common complaint. But it doesn't have to be! This talk gives an overview on how to monitor distributed applications. We dive into: System metrics: Keep track of network traffic and system load. Application logs: Collect structured logs in a central location. Uptime monitoring: Ping services and actively monitor their availability and response time. Application metrics: Get metrics and health via REST or JMX. Request tracing: Trace requests through a distributed system and Zipkin to show how long each call takes. And we will do all of that live, since it is so easy and much more interactive that way.

During this session, I will explain how we created a data pipeline to store and analyze trillions of domain events produced by microservices. Then, we will discuss how the underlying infrastructure is built in AWS using automation tools like Terraform, Puppet and Jenkins. Also we will talk about the Kafka ecosystem and how we use it together with Cassandra. At the end of the talk, we will show in a small demo the journey of a domain event passing through this pipeline until it is stored in S3 for further analysis.

My dad once told me about a guy from Birmingham, a martial artist who’d learned tai-kwon-do, who could do jujitsu and would box. Now, in his wisdom he devised his own style of martial arts, the principle was simple, if you couldn’t do it in a phone booth, it was no good to you in a pub fight. With two paragraphs about Birmingham, kung-fu and pub fights you might be wondering how this could ever have anything to do with practical DevOps. Introducing ChatOps, and here’s the tag line, when you’re in the pub, down the gym or stuck on a plane to New York, what’s the maximum you can do from just your phone. We don’t all lug around a laptop 24⁄7 and I know I don’t always have a handbag big enough for mine, so if your production environment was burning down, and all you had was your phone, data and slack, could you save it all?

As a beginner, finding your place and grasping the idea of DevOps is very much depending on the personal motivation and the environment you work. They did not teach you this in schools. In this talk, I am going to share my journey. You will see the representation of a story that adopts the DevOps as a mindset rather than people, tools and so on. The talk will be a story-line that is supported by real-world examples such as using the tools, communication in the teams etc. from the experiences of a Junior Engineer’s road-map to DevOps.

Today’s data centers aren’t the same anymore. We are constantly moving from one set of technologies to the other. We often find it hard to connect newly deployed applications to rest of our infrastructure. See how to use Consul to help connect applications across your infrastructure. Consul is an open source tool for service discovery, monitoring, and globally distributed key-value store. In this talk we will cover how Consul can help bridge the gap between various types of applications that might exist in a datacenter at any given time. As we move towards micro service oriented architectures we find ourselves using cluster schedulers like Kubernetes and Nomad. We will discuss how Consul’s service discovery features help connect applications running in such environments. We will also explore how we can connect applications that are running in traditional environments to ones running in these cluster schedulers using Consul’s API and built in DNS support. We will do a live demo of connecting two applications running in separate environments using Consul and showcase important features of Consul.

We will discuss the different stages that Facebook went through for operations automation as the number of servers grew, introduce some key concepts applicable to any company that wants to scale their operations teams as their fleet grows, and describe the frameworks we developed in Python to automate away most of the manual operations work.

Although QAs and Devops can be seen as two different roles, the truth is that they have more things in common than we think. When we are creating the structure of our test suites we need to take into account some practices and tools devops normally use in their daily work. From integrating the test automation with the CI tool to catching bugs as soon as possible to the use of containers to speed up test executions. In this talk we are going to discover the different tips and tricks that makes QAs and Devops best friends.





Auditori L'illa
Avinguda Diagonal, 547, 08029 Barcelona
Copyright 2026 - Devops Barcelona Conference is organized by Rigor Guild S.L. (ESB67337832)
Gran Via de les Corts Catalanes, 521, Principal 1, 08015, Barcelona, Spain